简介本文对C++数据结构知识进行总结,供C++开发岗位求职者参考。
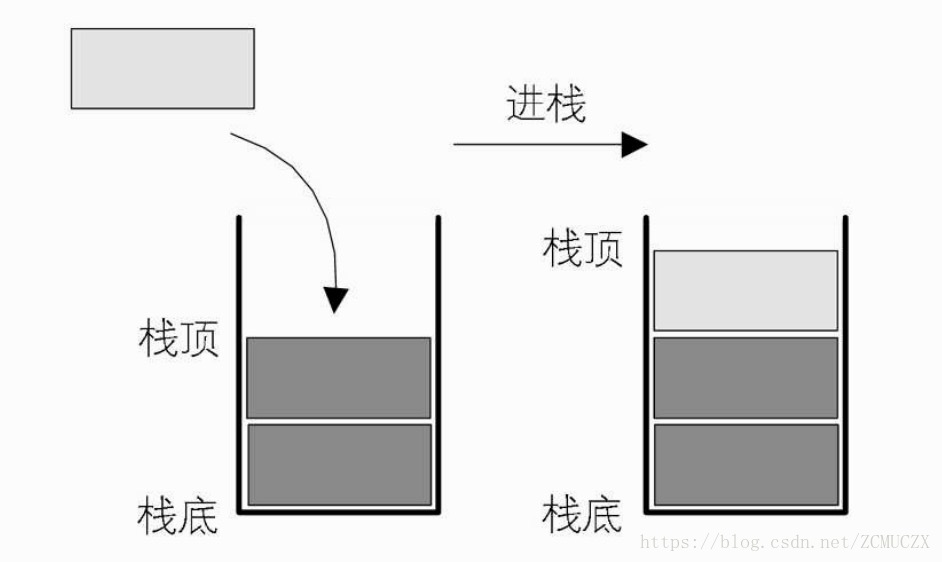
栈的核心是LIFO(Last In First Out),即后进先出
出栈和入栈只会对栈顶进行操作,栈底永远为0
栈底(bottom):栈结构的首部
栈顶(top):栈结构的尾部
出栈(Pop):结点从栈顶删除
进栈(Push):结点在栈顶位置插入
取栈顶内容操作(Top):取栈顶结点数据值的操作
空栈:当栈中结点数为0时
如果是入栈,要将入栈元素赋值给栈数组,再将栈顶上移一位:
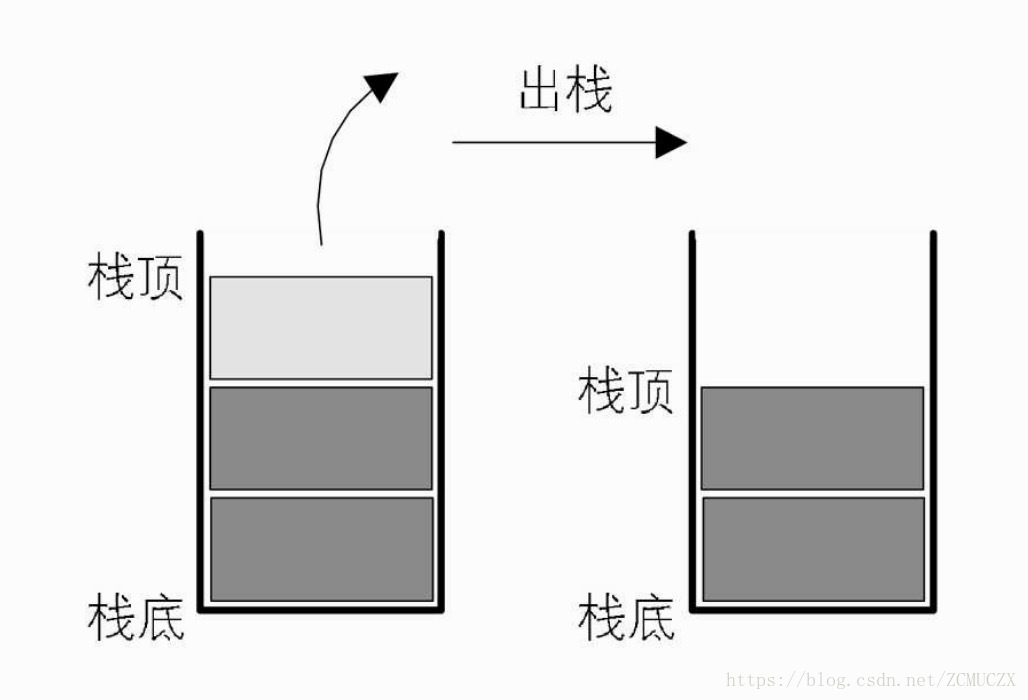
出栈时要先将栈顶下移一位,再将栈顶元素赋值给引用
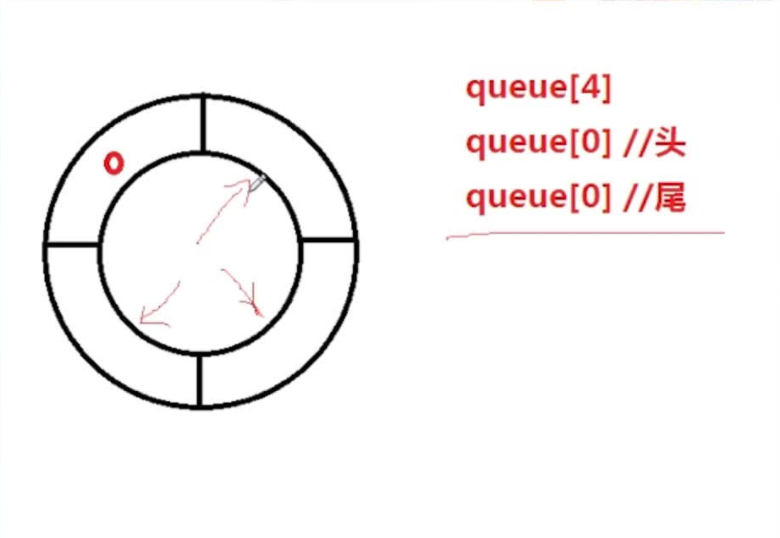
普通队列效率低下,出队的时候头数组要清空,后面的元素都要向前移动
环形队列判空判满不能用head = tail判断,因为队满和队空都满足这种条件
这里只讨论环形队列
队列的核心思想是FIFO(First In First Out),即先入先出
队首(front):队列首元素
队尾(rear):队列尾元素
出队(Dequeue):把结点从队首删除的操作
入队(Enqueue):在队尾位置插入的操作
入队(新增元素)必须从队尾加入,出队(删除元素)必须从队首出去
线性表:是零个或多个数据元素的有限序列
需要注意的是:
如图按下标排序的数据元素就可以认为是一个线性表:

线性表长度:线性表中数据元素个数称为线性表的长度, 长度为零的表称为空表.
前驱:某个数据元素的前一个数据元素称为该元素的前驱, 每个元素至多有一个前驱.
后继:某个数据元素的后一个数据元素称为该元素的后继, 每个元素至多有一个后继.
线性表的两种存储结构:
根据线性表中数据元素在内存中的存储方式可以用顺序存储结构或链式存储结构实现线性表.
用顺序存储结构即使用 数组 来表示线性表元素之间的顺序和对应关系. 用链式存储结构即使用 指针 来表示线性表元素之间的顺序和对应关系, 我们称其为 链表 .
核心操作
3.2.1插入元素
先判断索引是否合法
索引如果合法
先对插入元素的位置后面进行移动,并且是倒序移动,因为顺序移动顺序表前面的元素值会一直覆盖掉后面的
假如按顺序插入,如:
list1->ListInsert(0, &e1);
list1->ListInsert(1, &e2);是不会进入for循环的,只有插入同一个位置,才会向后移动元素
移动完元素后进行赋值操作
长度++
PS:这里m_pList[k+1] = m_pList[k]写成m_pList[k] = m_pList[k-1]效果是一样的,那么上面k就要等于m_iLength = m_iLength,不然顺序表尾元素会丢失掉
bool List::ListInsert(int i, int *Elem)
{
if (i<0 || i>m_iLength)
{
return false;
}
else
{
//先在后面进行移动
for (int k = m_iLength - 1; k >= i; k--)
{
m_pList[k + 1] = m_pList[k];
}
//插入元素
m_pList[i] = *Elem;
m_iLength++;
return true;
}
}3.2.2删除元素
对索引判断是否合法
然后先将要删的元素赋值给Elem所指向空间的值,后赋值,元素已经被删掉,获取不到了
从前往后移动,从后面往前移动会造成元素值的丢失
移动完毕
长度--
bool List::ListDelete(int i, int *Elem)
{
if (i<0 || i>=m_iLength)
{
return false;
}
else
{
*Elem = m_pList[i];
//先在前面进行移动,从后面开始移动会造成值的替代
//k=i+1对应着k-1,若k=i,k <= m_iLength-1,m_pList[k] = m_pList[k+1];
for (int k = i+1; k <= m_iLength; k++)
{
m_pList[k-1] = m_pList[k];
}
m_iLength--;
return true;
}
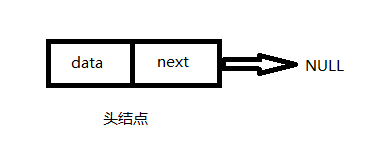
}头结点:不算在数组索引中,数据域为空,指针域指向开始的结点
核心操作:
3.3.1插入元素:
判断参数i的合法性
i不能小于0,i不能大于链表长度,i等于链表长度代表可以尾元素后插入
currentNode保存头结点
声明newNode
pNode数据域赋值给newNode数据域
新结点指向原来结点的下一个结点
原来的结点指向新结点

bool List::ListInsert(int i, Node *pNode)
{
if (i<0 || i>m_iLength)
{
return false;
}
Node *currentNode = m_pList;
for (int k = 0; k < i; k++)
{
currentNode = currentNode->next;
}
Node *newNode = new Node;
if (newNode == NULL) //判断申请的结点内存是否为空
{
return false;
}
else
{
newNode->data = pNode->data;
newNode->next = currentNode->next;
currentNode->next = newNode;
return true;
}
}3.3.2删除元素:
判断i是否合法,索引最大是m_iLength-1,和循环条件k<i对应
currentNode保存头指针
currentNodeBefore置空
currentNodeBefore指向currentNode的下一个结点的指针域,这样currentNode就可以被删除释放了
pNode数据域接收当前结点的数据域
删除当前结点并置空

bool List::ListDelete(int i, Node *pNode)
{
if (i<0 || i>=m_iLength)
{
return false;
}
Node *currentNode = m_pList;
Node *currentNodeBefore = NULL;
for (int k = 0; k <= i; k++)
{
currentNodeBefore = currentNode;
currentNode = currentNode->next;
}
currentNodeBefore->next = currentNode->next;
pNode->data = currentNode->data;
delete currentNode;
currentNode = NULL;
m_iLength--;
return true;
}
核心操作:
4.2.1添加结点:
direction = 0代表添加左子节点,direction = 1代表添加右子节点
左子节点 = 2*索引+1;右子节点 = 2*索引+2
下图可以验证

继续判断索引的合法性,左子节点和右子节点同样不能小于0或者大于等于数组长度
最后将*pNode赋值给子节点
bool Tree::AddNode(int nodeIndex, int direction, int *pNode)
{
if (nodeIndex<0 || nodeIndex >= m_iSize)
{
return false;
}
if (m_pTree[nodeIndex] == 0)
{
return false;
}
if (direction == 0)
{
//nodeIndex * 2 + 1<0可以省略
if (nodeIndex * 2 + 1<0 || nodeIndex * 2 + 1 >= m_iSize)
{
return false;
}
//判断是否有左子节点
if (m_pTree[nodeIndex * 2 + 1] != 0)
{
return false;
}
m_pTree[nodeIndex * 2 + 1] = *pNode;
}
if (direction == 1)
{
//nodeIndex * 2 + 2<0可以省略
if (nodeIndex * 2 + 2<0 || nodeIndex * 2 + 2 >= m_iSize)
{
return false;
}
//判断是否有左子节点
if (m_pTree[nodeIndex * 2 + 2] != 0)
{
return false;
}
m_pTree[nodeIndex * 2 + 2] = *pNode;
}
return true;
}4.2.2删除结点:
判断索引和数组值的合法性
将*pNode接收删除的对应索引的数组
将该索引数组置为0,结点值等于0代表删除
返回正确结果
bool Tree::DeleteNode(int nodeIndex, int *pNode)
{
if (nodeIndex<0 || nodeIndex >= m_iSize)
{
return false;
}
if (m_pTree[nodeIndex] == 0)
{
return false;
}
*pNode = m_pTree[nodeIndex];
m_pTree[nodeIndex] = 0;
return true;
}核心操作:
前序遍历:根左右
中序遍历:左根右
后序遍历:左右根
void Node::PreorderTraversal()
{
cout << this->index<<" "<<this->data << endl;
if (this->pLChild != NULL)
{
this->pLChild->PreorderTraversal();
}
if (this->pRChild != NULL)
{
this->pRChild->PreorderTraversal();
}
}
void Node::InorderTraversal()
{
if (this->pLChild != NULL)
{
this->pLChild->InorderTraversal();
}
cout << this->index << " " << this->data << endl;
if (this->pRChild != NULL)
{
this->pRChild->InorderTraversal();
}
}
void Node::PostorderTraversal()
{
if (this->pLChild != NULL)
{
this->pLChild->PostorderTraversal();
}
if (this->pRChild != NULL)
{
this->pRChild->PostorderTraversal();
}
cout << this->index << " " << this->data << endl;
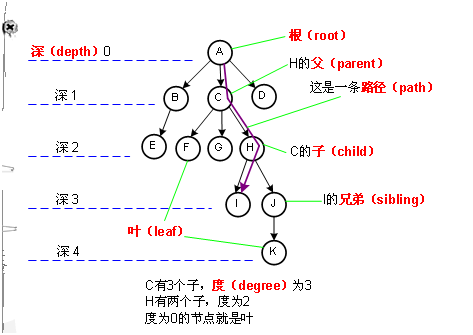
}图: 简单的说,图是一个用线或边连接在一起的顶点或结点的集合,严格的说,图是有限顶点V和边E的有序对
有向边: 带有方向的边
无向边: 没有方向的边
权 :在图的一些应用中,要为每条边赋予一个表示大小的值,这个值就称为权
连通图 :设图G是无向图,当且仅当G的每一对顶点之间都有一条路径,则称G是连通图
生成树 :如果图H是图G的子图,且他们的顶点集合相同,并且H是没有环路的无向连通图(即一棵树),则称H是G的一棵生成树
极大连通子图: 连通图本身
极小连通子图: 为其生成树
连通分量: 无向图的极大连通子图
出度: 从该顶点出发的边数
入度: 到达该顶点的边数
深度优先搜索: 树的前序遍历
广度优先搜索: 按层次来遍历的树的前序遍历
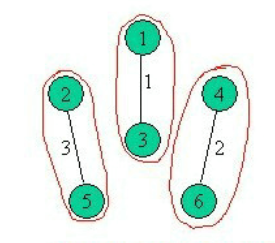
如图,存在三个连通分量
子图 :如果图H的顶点和边的集合是图G的子集,那么称图H是图G的子图
强连通图 :图G是一个有向图,当且仅当每一对不同的顶点u,v,从u到v和v到u都有一条有向路径
核心操作:
5.2.1为有向图设置邻接矩阵:
判断行列的合法性
如果行小于0,行大于等于最大容量,返回错误
如果列小于0,列大于等于最大容量,返回错误
图如下:
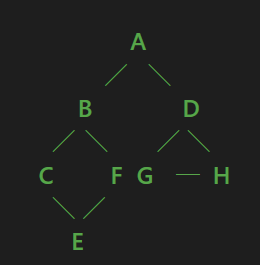
上图的邻接矩阵如下:

以(A,B)即(0,1),0行1列,0*8+1=1。
满足row*m_iCapacity+col计算的索引
bool cMap::setValueToMatrixForDirectedGraph(int row, int col, int val)
{
if(row<0 || row>=m_iCapacity)
{
return false;
}
if (col < 0 || col >= m_iCapacity)
{
return false;
}
m_pMatrix[row*m_iCapacity + col] = val;
return true;
}

本文向大家介绍一个C++实战项目:C++实现雪花算法(SnowFlake)产生唯一ID,主要涉及雪花算法、算法知识等,具有一定的C++实战价值,感兴趣的朋友可以参考一下。

本文介绍C++实现C++实现8种排序算法,主要包括冒泡排序、插入排序、二分插入排序、希尔排序、直接选择排序、堆排序、归并排序、快速排序,直接上代码,感兴趣的朋友可以参考一下。

本文介绍一个C++代码片段:如何在C++中删除一个文件目录下的所有文件及目录,感兴趣的朋友可以参考一下。

本文介绍C++实现线程同步的四种方式:事件对象、互斥对象、临界区、信号量,感兴趣的朋友可以参考一下。
本文介绍C++内存泄漏的检测与定位方法,感兴趣的朋友可以参考一下。
本文实现C++中UTF-8与GB2312相互转换,感兴趣的朋友可以参考一下。